
Scaling with Nginx; Cost-Performance analysis

When you realize your system is getting slow and is unable to handle the current number of requests even with optimizations, you need to scale the system sooner than you can optimize further. Building a scalable system also drives to a lower Total Cost of Ownership (TCO). Proper scaling in process-intensive applications embraces interesting new scenarios, notably in data analytics and machine learning. Traditionally, you have two options, Horizontal scaling, and Vertical scaling.
Pokémon Go - A Successful Scaling Story
If you downloaded the Pokémon GO app right at its launch, you might have faced several issues on server unavailability for some minutes. Based on the hype around the announcement of Pokémon GO, one might have already presumed what chaos was going on in the backend infrastructure. Pokémon Go engineers never imagined their user base would grow exponentially, exceeding the expectations within a short time. With 500+ million downloads and 20**+** million daily active users, the actual traffic was 50 times more than their initial expected traffic.
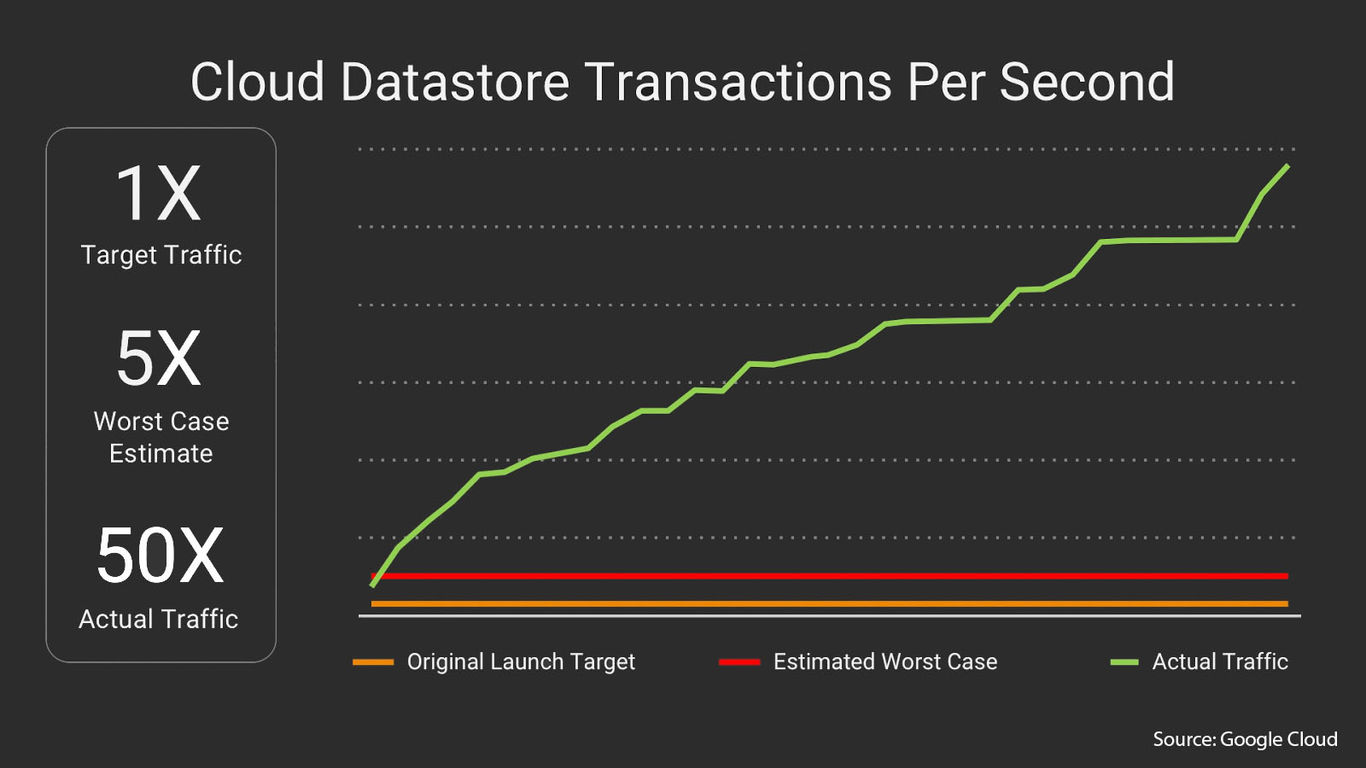
This makes Pokémon GO, one of the most exciting examples of container-based development and scaling in the wild. The logic for the game runs on Google Container Engine (GKE) powered by Kubernetes. Niantic picked GKE for its capability to orchestrate their container cluster at large-scale, saving its focus on deploying live changes for their players. So by provisioning tens of thousands of cores for Niantic’s Container Engine cluster, the game brought joy into all the Pokémon Trainers around the globe.
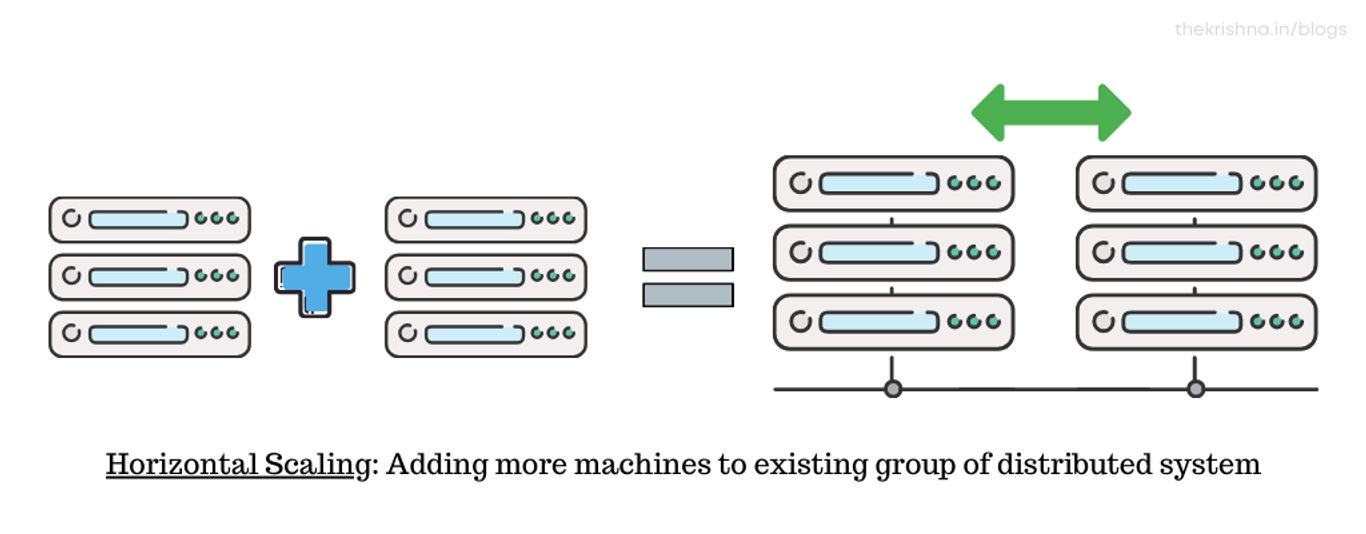
What is Horizontal scaling?
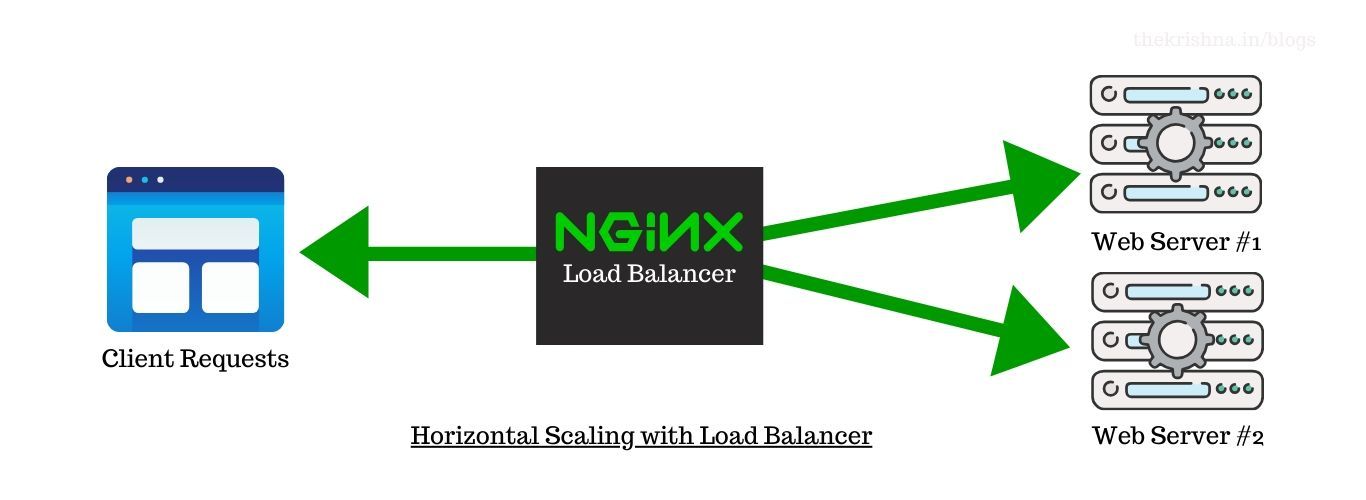
Horizontal scaling implies that you scale a cluster by attaching more machines or nodes into your pool of resources. Scaling horizontally is like thousands of minions will do the work together for you. Increasing the number of servers present in a system is the highly used solution is in the tech industry. This will eventually decrease the load in each node while providing redundancy and flexibility, thus reducing the risks of downtimes. If you need to scale the system, just add another server, and you are done.
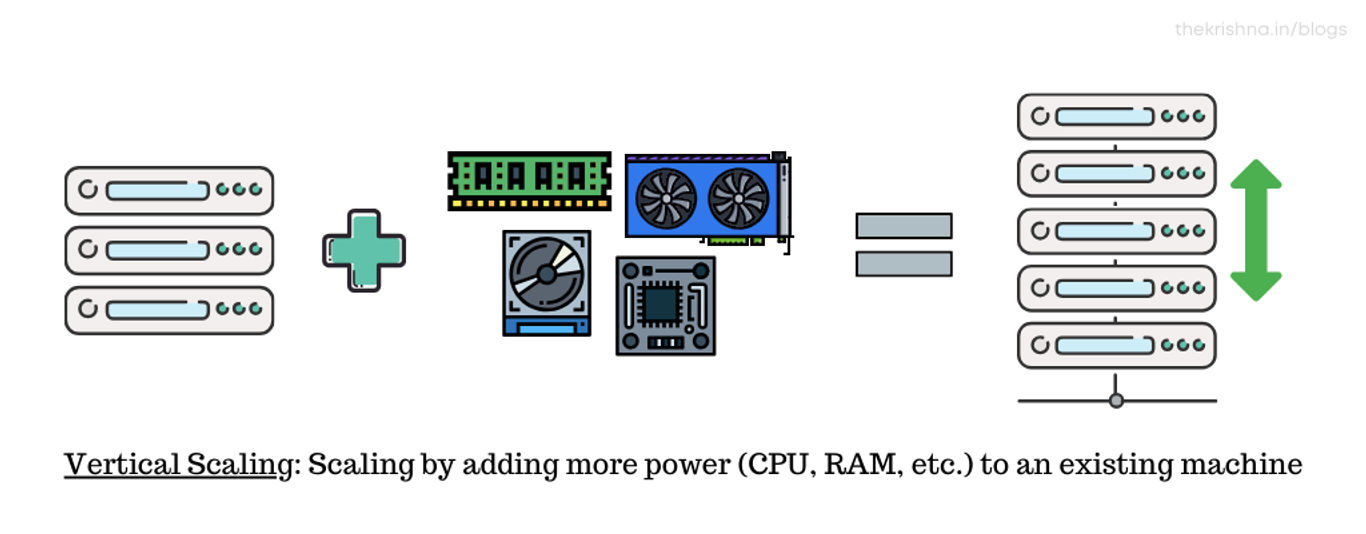
What is Vertical scaling
Vertical scaling means that you scale by adding horsepower to an existing machine. Scaling vertically is like one big hulk will do all the work for you. You increase the resources in the server which you are using currently (increase the amount of RAM, CPU, GPU, and other resources). A horizontally scaled app will provide the benefit of elasticity. Vertical scaling is expensive than horizontal scaling and may require your machine to be brought down for a moment when the process takes place.

I’ve explained in brief about nginx and how to run it using docker in my previous post
Getting Started
As developers, we do not always have access to a production-like environment to test new features and run proofs-of-concept. This is why it can be interesting to deploy containers for such an experiment. For this little experiment, our host machine (part of my home-lab setup) comes with a 4-core Intel i5-4200M (base speed of 2.5 GHz) and dedicated 6GB DDR3 SDRAM.
Now the client uses the ab - Apache HTTP server benchmarking tool. For ensuring connection stability and integrity, both our host machine and our client will be connected via Ethernet on an isolated network. The cost is determined based on their highest on-demand value based on AWS-EC2 and Sherweb pricing with a fixed storage and network bandwidth.
Diving into action
We’ll be requesting the below HTML document from our Nginx server. As you can see here, there are no references to increase unnecessary load times. The HTML Document Length is 1328 bytes, and our server is running nginx/1.19.0.
Initial Benchmark
Our initial benchmark is on a single docker container with 4MB memory, and 0.1 CPU cores. Docker can allocate partial CPU cores by adjusting the CPU CFS scheduler period, and imposing a CPU CFS quota on the container. To kick things up a notch, I used 10000 requests with 1000 concurrencies.
# ab -n <num_requests> -c <concurrency> <addr>:<port><path>
ab -n 10000 -c 1000 http://192.168.1.16/index.html
Observations
- It took the server about 31.462 seconds to transfer 14.89 MB (15620000 bytes)
- Fastest request was served at 50ms and slowest at 20796ms.
- This request time was high due to high concurrency and wasn’t the same case when concurrency is 1000 and below.
Vertical Scaling
Like above, our benchmarking parameters are 10,000 requests with a concurrency of 1000 .
Tabulated Result
| # | CPU Cores | Memory (MB) | Time Taken (s) | Request Per Second | Transfer rate (KBps) | Min. Serve Time (ms) | Max. Serve Time (ms) | Time per request (ms) | Estimated Monthly Cost (USD) |
|---|---|---|---|---|---|---|---|---|---|
| A | 0.1 | 2 | 64.614 | 154.77 | 234.1 | 47 | 64,537 | 6.461 | 0.51 |
| B | 0.3 | 6 | 50.657 | 196.42 | 289.17 | 47 | 35,162 | 5.091 | 2.02 |
| C | 0.5 | 10 | 39.327 | 254.28 | 376.24 | 49 | 33,404 | 4.133 | 3.36 |
| D | 0.7 | 14 | 35.985 | 277.89 | 412.15 | 42 | 31,926 | 3.599 | 4.72 |
| E | 1 | 20 | 29.238 | 338.19 | 505.88 | 51 | 29,189 | 2.957 | 6.81 |
Horizontal Scaling
Like above, our benchmarking parameters are 10,000 requests with 1000 concurrencies. Each instance would have 0.1vCPU and 2MB of Memory and are deployed using Nginx Ingress Controller in a Minikube cluster.
Tabulated Result
| # | Number of Instances | Time Taken (s) | Request Per Second | Transfer rate (KBps) | Min. Time to Serve (ms) | Max. Time to Serve (ms) | Time per request (ms) | Estimated Monthly Cost (USD) |
|---|---|---|---|---|---|---|---|---|
| A | 1 | 64.614 | 154.77 | 234.1 | 47 | 64537 | 6.461 | $0.51 |
| B | 3 | 46.802 | 212.42 | 317.54 | 45 | 24473 | 4.701 | $1.53 |
| C | 5 | 34.334 | 284.28 | 403.43 | 43 | 23249 | 3.817 | $2.55 |
| D | 7 | 30.247 | 311.89 | 461.11 | 44 | 22220 | 3.324 | $3.57 |
| E | 10 | 24.013 | 437.19 | 551.25 | 49 | 20316 | 2.731 | $5.10 |
Final Result: Vertical Scaling v/s Horizontal Scaling
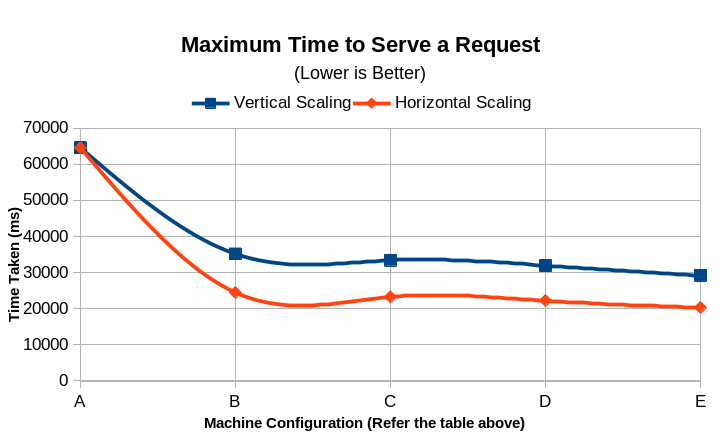
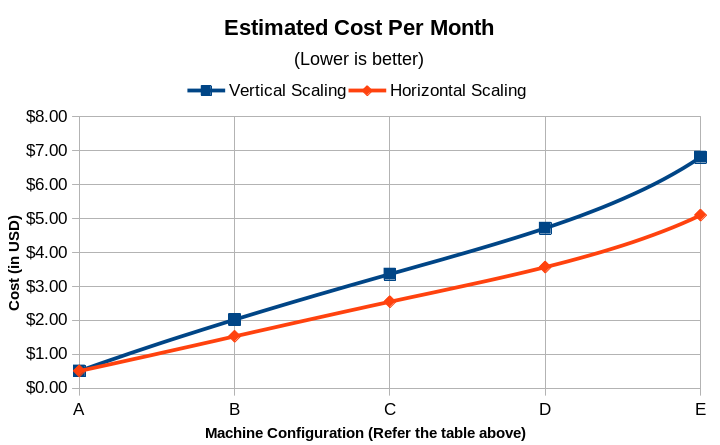
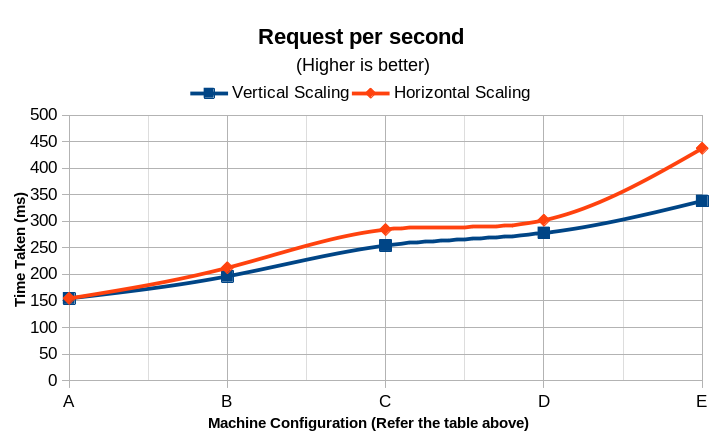
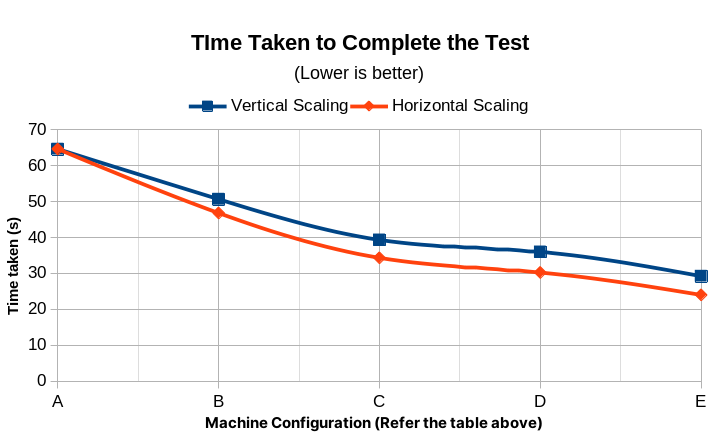
Observations
- The overall performance degrades if the increase in CPU cores allocated was not proportional to the memory allocated. This is because the data must be read from the disk instead of directly from the data cache, causing a memory bottleneck.
- The vice-versa can also happen and is termed as CPU-Bottlenecks which causes a chronically high CPU utilization rate.
- On Vertical Scaling, Our test roughly stabilized after 1 CPU core and 32 MB of memory. This signifies that more than the required resources will not result in a performance boost, but will only increase our cost of the deployment.
Conclusion
From the above, we understood the following:
- Horizontal Scaling provides a faster delivery than vertical scaling due to their lower average request time.
- In terms of responsiveness, Horizontal Scaling provides better performance due to the distribution of server loads among available nodes.
- Horizontal scaling prevents you from getting caught in a resource deficit.
- Horizontal Scaling is more cost-effective than vertical scaling.
But this doesn’t mean all applications would qualify for absolute horizontal scaling. If your applications demand a greater horsepower to perform as expected or quicker, you might want to consider vertical scaling. In other words, you might want each of your thousands of minions as powerful as a hulk, so they are suitable for other intensive tasks. But for accurate lower Total Cost of Ownership (TCO), Auto Scaling is the solution. Here, servers dynamically scale to secure steady, predictable performance at the lowest possible cost.